FRIDA
Drought detection and monitoring in highly regulated water systems is a challenging modeling problem because many human-controlled variables (e.g., reservoirs and groundwater levels) as well as uncontrolled hydro-meteorological variables (e.g., precipitation, temperature, natural inflows) may in principle contribute to the onset of a drought. The definition of basin-specific drought indexes requires to identify an optimal subset of candidate drought predictors and to define how to effectively combine them balancing index accuracy and compactness.
We propose FRIDA (FRamework for Index-based Drought Analysis), a fully-automated and generalizable framework for the design of basin-customized drought indexes (Zaniolo et al., 2018). This page allows interested readers to get familiar with FRIDA and to reproduce our results.
Dataset
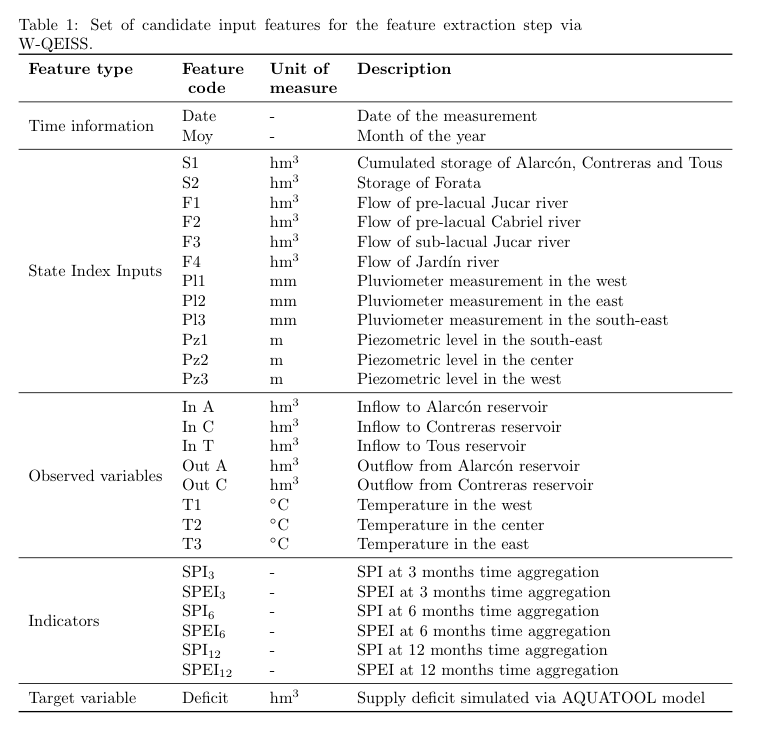
The complete dataset employed in the feature selection step can be downloaded open source from Zenodo. The matrix processed data – input WQEISS.csv reports the monthly values of the 28 predictors and target variable for the period 1986-2000, including:
- 2 temporal features: day and month of the year;
- 12 inputs to the Jucar State Index: average monthly storage and groundwater levels, average three months river runoff, and cumulated areal precipitation over 12 months;
- 8 additional observed variables in the basin: three months average outflows from, and inflows to, the main reservoirs, and mean monthly areal temperatures;
- 6 traditional drought indicators: Standardized Precipitation Index (SPI) and Standardized Precipitation and Evaporation Index (SPEI). SPI and SPEI indicators are computed on mean monthly data over the entire basin for 3, 6, and 12 months time aggregations.
The last column of the dataset reports the target variable, i.e., the monthly nominal shortage of water conveyed to the irrigation districts simulated via AQUATOOL model. Further details about the candidate inputs are reported in Table 1 below. The unprocessed data used to compute indices, averages and cumulations at different time aggregations are provided by the Confederación Hidrográfica del Jucar and reported in table Raw Data.csv. Public observations of rainfall, streamflows and storage levels come from the SAIH (Hydrological Automatic Information System) of the CHJ (Jucar Hydrological Confederation). Users can directly download data for the last 12 months on the dedicated webpage, while previous data records are provided for free by CHJ upon request. Observations from piezometers are downloadable from the Piezometric Network Information section section of the CHJ website.
Wrapper for Quasi-Equally Informative Subset Selection (W-QEISS)
The code for W-QEISS (Karakaya et al., 2015; Taormina et al., 2016) is available on GitHub. The experimental settings employed in our analysis are the following: the number of function evaluation (NFE) for Borg MOEA was set equal to 2 millions, while the number of hidden neurons in the ELM model was set to 30; the k-fold cross-validation process (with k = 10) is repeated 5 times and the average resulting value is used to estimate the predictive accuracy of each model; the W-QEISS experiment with such setting is run 20 times to filter out the random component of the process, and the final result is obtained by merging the Pareto fronts of each repetitions into a final Pareto front of non-dominated solutions.